If divisor is fixed, the division operation can be replaced by multiplication by a reciprocal; the idea is very simple: x / d = x * (1/d); since d is fixed we can precompute 1/d and use faster multiplication operation. This trick works for integer division, with some additional complications. For example, the next function is identical to division by 5 for all 32-bit dividends:
function Div5(Dividend: LongWord): LongWord;
const
Mult = $CCCCCCCD;
PostSh = 2;
asm
MOV EDX,Mult
MUL EDX
MOV EAX,EDX
SHR EAX,PostSh
end;
It turns out that 32-bit multiplication constant does not exists for every divisor; in this case it is possible to use 33-bit constant with hidden senior 1 bit:
function Div5_2(Dividend: LongWord): LongWord;
const
Mult = $9999999A;
PostSh = 3;
asm
MOV ECX,EAX // save dividend
MOV EDX,Mult
MUL EDX
MOV EAX,ECX // restore dividend
ADD EAX,EDX
RCR EAX,1 // because addition could produce carry
SHR EAX,PostSh-1
end;
Naively, the multiplication constant ($9999999A) and postshift (3) can be obtained using the following steps:
1. Write 1/5 in binary form: 1/5 = 0.0011 0011 0011 0011 0011 ..
2. Count leading zeroes after decimal point and add 1; this gives the postshift
3. Write the leading significant bits:
1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 ..
4. Round to 33 bits; rounding is not necessarily based on the value of 34th bit only (later we will use a different approach which is free from rounding problem)
1100 1100 1100 1100 1100 1100 1100 1100 1101 0
5. Remove the leading bit and write as hexadecimal to get the multiplication constant:
99 99 99 9A
The second version is more complicated, but good news is that it works for all divisors. Generally, it can be proven that for N-bit division there exists (N+1) bit multiplication constant – for the details see the key article Division by Invariant Integers using Multiplication. The rest of the post is a review of the results obtained in the article cited. I will use 32-bit arithmetic, but the results can be generalized for any bitness.
The multiplication constant and postshift can be found using the following procedure:
procedure GetParams(Divisor: LongWord);
var
L, N: LongWord;
Tmp: LongWord;
M: UInt64;
Mult: LongWord;
begin
Assert(Divisor > 1);
Tmp:= Divisor;
L:= 0;
repeat // count number of significant bits in Divisor
Tmp:= Tmp shr 1;
Inc(L);
until Tmp = 0;
N:= 1 shl L; // N = 2^L
M:= $100000000; // 2^32
M:= (M * (N - Divisor)) div Divisor + 1;
Mult:= LongWord(M);
Writeln('Mult = ' + IntToHex(Mult, 8));
Writeln('Shift = ' + IntToStr(L));
end;
The multiplication constant is not unique. If the constant obtained from the above procedure is odd, it makes sense to increment it by 1 (provided the incremented constant is correct too). The correctness can be checked by
function CheckMult(Divisor, Mult: LongWord): Boolean;
var
L, N: LongWord;
Tmp: LongWord;
P32, MD: UInt64;
Min, Max: UInt64;
begin
P32:= $100000000; // 2^32;
MD:= (P32 + Mult) * Divisor;
L:= 0;
Tmp:= Divisor;
repeat // count number of significant bits in Divisor
Tmp:= Tmp shr 1;
Inc(L);
until Tmp = 0;
N:= 1 shl L;
Min:= P32 * N;
Max:= Min + N;
Result:= (Min <= MD) and (MD <= Max);
end;
The above function gives sufficient condition for correct multiplication constant; it is probably possible that some constant fails the check but still correct, as can be shown by the full search over the dividend range; we will not consider this case.
Optimization 1. If the multiplication constant is even, we can shift it right and fit into 32-bit range, thus obtaining shorter division algorithm; this also decrements the postshift.
As an example consider division by 641. The GetParams procedure returns
Mult = 98F603FF
Shift = 10
Since the multiplication constant is odd, we try incremented constant 98F60400. CheckMult shows that it is correct too; the constant ends with 10 zero bits, which is equal to postshift, so we eliminate the postshift:
function Div641(Dividend: LongWord): LongWord;
const
Mult = $663D81; // = $198F60400 shr 10
asm
MOV EDX,Mult
MUL EDX
MOV EAX,EDX
end;
Optimization 2. If the divisor is even, we can preshift both dividend and divisor right, thus decreasing the required precision and obtaining shorter division algorithm again (with the dividend preshift step). For details see the article cited above.



 , where
, where  stands for xor operation.
stands for xor operation. possible strategies. Since the probability of
possible strategies. Since the probability of  is 75%, it can be easily seen that there exists 75%-winning strategy – Alice and Bob simply ignore the questions and answer identically – either by bit 0 both or by bit 1 both; it seems natural that this is the best strategy, and it is indeed so, as can be formally shown by checking all 16 possible strategies.
is 75%, it can be easily seen that there exists 75%-winning strategy – Alice and Bob simply ignore the questions and answer identically – either by bit 0 both or by bit 1 both; it seems natural that this is the best strategy, and it is indeed so, as can be formally shown by checking all 16 possible strategies.
 :
:

 on receiving the question 0, and
on receiving the question 0, and  on receiving the question 1; Bob uses
on receiving the question 1; Bob uses  on receiving the question 0, and
on receiving the question 0, and  on receiving the question 1.
on receiving the question 1. , Alice and Bob win if they answer identically
, Alice and Bob win if they answer identically  or
or  . The correspondent probability of winning (given
. The correspondent probability of winning (given 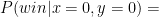

 we get
we get
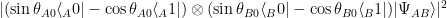
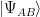 we get
we get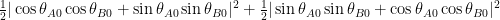

 and
and  are similar to
are similar to 

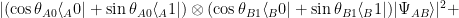



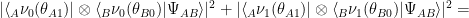



 Alice and Bob win if they answer differently, so:
Alice and Bob win if they answer differently, so: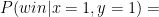

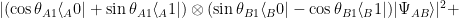


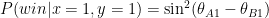

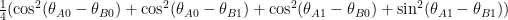
 , then
, then 

 for
for  :
:
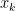 for
for



 ; next,
; next,
 or
or  ; checking the first alternative gives
; checking the first alternative gives  , so
, so 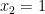 ; next,
; next, ; checking
; checking  gives
gives  , so
, so  ; next,
; next, ; checking
; checking  gives
gives  , so
, so  ; finally,
; finally, ; checking
; checking  gives
gives  , so
, so  .
. .
.